
Hi,
I’m interested in the cache-aware prefetch algorithm mentioned in section 4.2 of the xgboost paper. I’m new to computer architecture and high-performance computing. I’ve tried to figure it out myself for many days but still don’t have an answer, so I hope to get some help here.
I assume the relative code is in https://github.com/dmlc/xgboost/blob/2fcc4f2886340e66e988688473a73d2c46525630/src/tree/updater_colmaker.cc#L381-L398:
int i;
const Entry *it;
const int align_step = d_step * kBuffer;
// internal cached loop
for (it = begin; it != align_end; it += align_step) {
const Entry *p;
for (i = 0, p = it; i < kBuffer; ++i, p += d_step) {
buf_position[i] = position_[p->index];
buf_gpair[i] = gpair[p->index];
}
for (i = 0, p = it; i < kBuffer; ++i, p += d_step) {
const int nid = buf_position[i];
if (nid < 0 || !interaction_constraints_.Query(nid, fid)) { continue; }
this->UpdateEnumeration(nid, buf_gpair[i],
p->fvalue, d_step,
fid, c, temp, evaluator);
}
}
I understand that cache miss rate would be high when the values do not fit into the cache and they are stored in non-contiguous memory locations. By using the buffer buf_gpair, the values will then be fetched in a continuous way. What I don’t understand is the loop is still going over gpair one by one, wouldn’t it creates the same amount of cache misses?
The paper mentioned a naive implementation of split enumeration introduces immediate read/write dependency between the accumulation and the non-continuous memory fetch operation.
I also found an early presentation suggest use prefetch to change the dependency to long range.
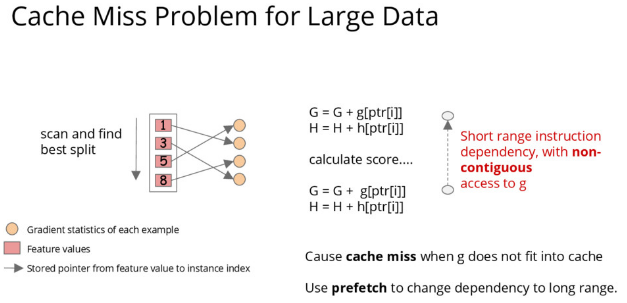
I have no ideas about the dependency impact here. Could anyone help me to understand the benefit of using the buffer? Really appreciate it!
Thanks,
JJ