
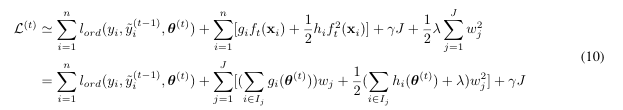
I am working on a custom loss function for the task of “Ordinal Classification” (not the same as learning-to-rank; here is an amazing blog post on loss function for ordinal classification), with an addition parameter (“theta”) to optimize other than w. I followed the boosting setup from the XGBoost paper. Mine requires performing convex optimization over the loss function to find the optimal theta, then we can proceed using the original formula (-sum_grad / (sum_hess + lambda)) to calculate the optimal leaf weight w. Here sum_grad (“g”) and sum_hess (“h”) both depend on “theta”
“theta” is a vector of non-decreasing thresholds on the real line that determine the predicted label (discrete, and ordinal) from the output score. There is definitely a common use case for recommendation systems.
However it is not clear to me how I can implement this in C++/Python. XGBoost currently does not support optimizing additional parameters in the model. I would love to gather some interest in the community to collaborate on this development.
What steps should I take to fully implement? I would really appreciate if someone could point me directions regarding what modification in the code-base I should do.