Hi,
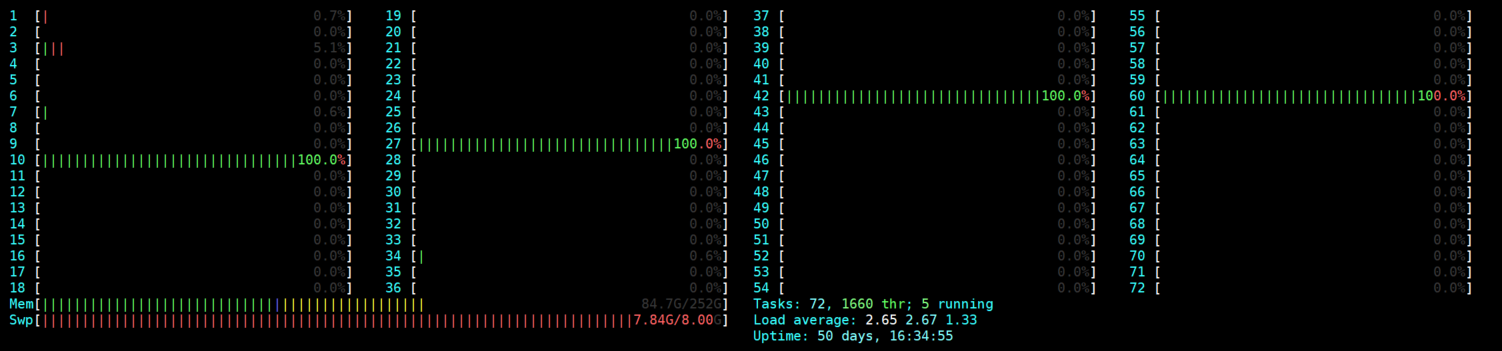
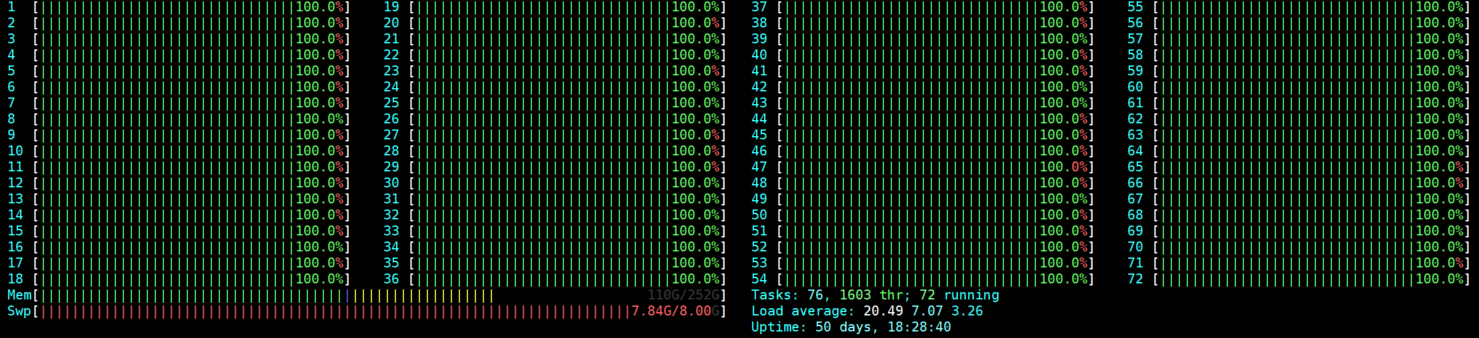
I am setting OMP_NUM_THREADS=36 but it is always using my max CPU value (72) in the XGBoost C++ code. I realized that when I printed ntrhead in the C++ code, for example, in src/common/quantile.cc:
int nthread = omp_get_max_threads(); --> edited this line after posting it.
This happens in these scenarios, when I set:
- Setting inside my python code: os.environ[‘OMP_NUM_THREADS’] = “36”
- Setting in my env: export OMP_NUM_THREADS=36
- Setting when calling the DMLC command line:
PYTHONPATH=~/xgboost/python-package/ ~/xgboost/dmlc-core/tracker/dmlc-submit --cluster=local --num-workers=1 OMP_NUM_THREADS=36 python3 myfile.py
Details:
Centos 7
lscpu: CPU(s): 72
My script:
import xgboost as xgb
xgb.rabit.init()
dtrain = xgb.DMatrix()
param = {
‘verbosity’: 3,
‘n_estimators’: 4
‘max_depth’: 8,
‘max_leaves’: 256,
‘reg_alpha’: 0.9,
‘learning_rate’: 0.1,
‘gamma’: 0.1,
‘subsample’: 1.0,
‘reg_lambda’: 1.0,
‘scale_pos_weight’: 2.0,
‘min_child_weight’: 30.0,
‘max_bin’: 16,
‘tree_method’: ‘hist’,
‘objective’: ‘multi:softmax’,
‘num_class’: 3,
‘grow_policy’: ‘lossguide’,
‘numWorkers’: 1
}
watchlist = [(dtrain,‘train’)]:set
bst = xgb.train(param, dtrain, num_round, watchlist)
xgb.rabit.finalize()
I understood that when setting OMP_NUM_THREADS=36, it should always use 36 threads to train the model. Is there a bug with OMP_NUM_THREADS?
Please advice if I am not using the variable in a correct way.
There is a past related issue: Predicting from multiple jobs & threading issues
Thank you.