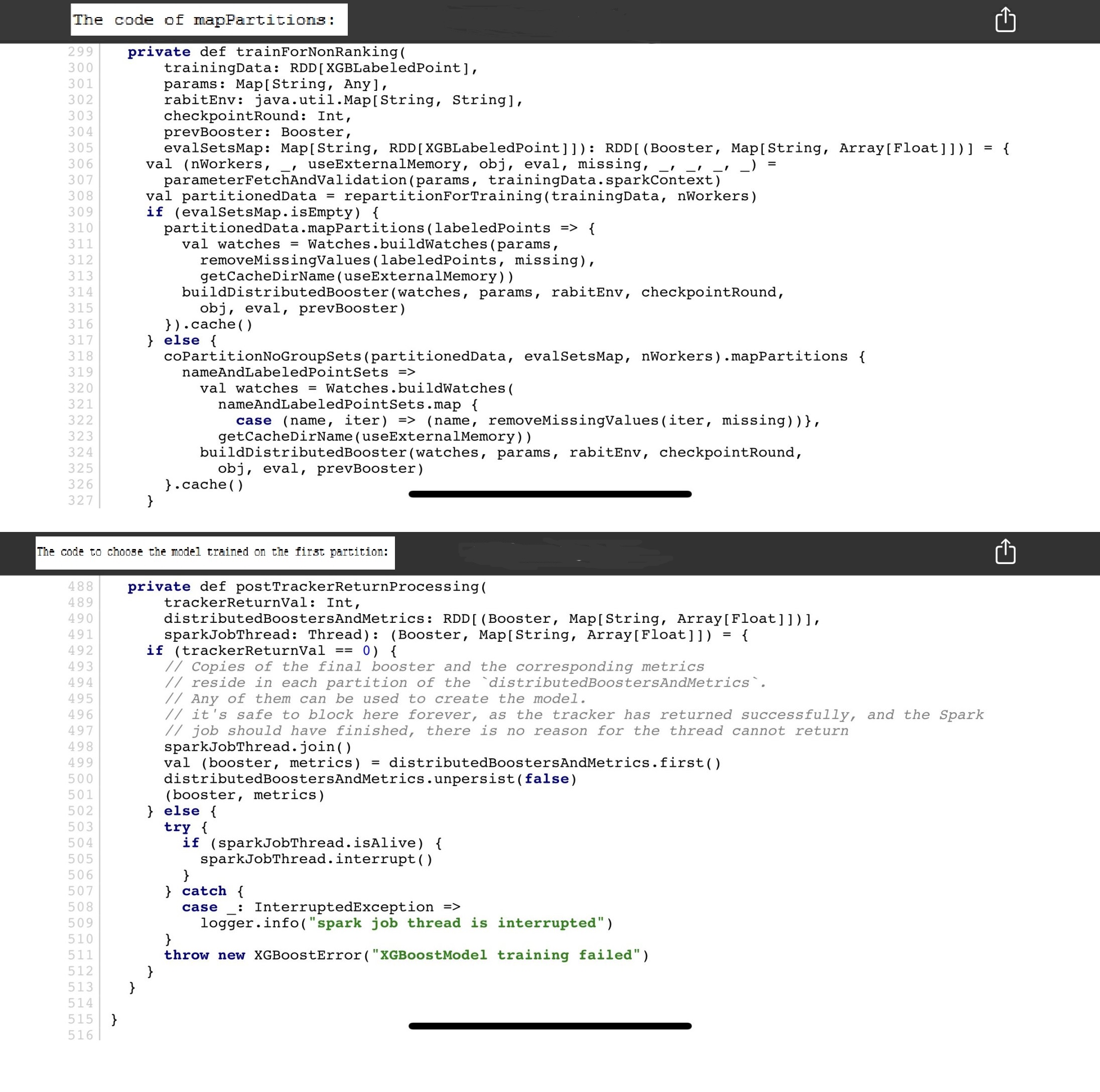
I get some OOM errors when I use xgboost4j-spark v0.82 on some big data. After going through the code, I find the degree of parallism is the partition number and it chooses the model trained on the first partition. It seems ridiculous that It only uses (1 / nWorkers) training data for the final model. Is there any misunderstanding?
The code of this spark verion is in
\jvm-packages\xgboost4j-spark\src\main\scala\ml\dmlc\xgboost4j\scala\spark\XGBoost.scala