When using weights with tree_method = “gpu_hist” in R, on relatively big data sizes, xgboost sometimes creates different solutions.
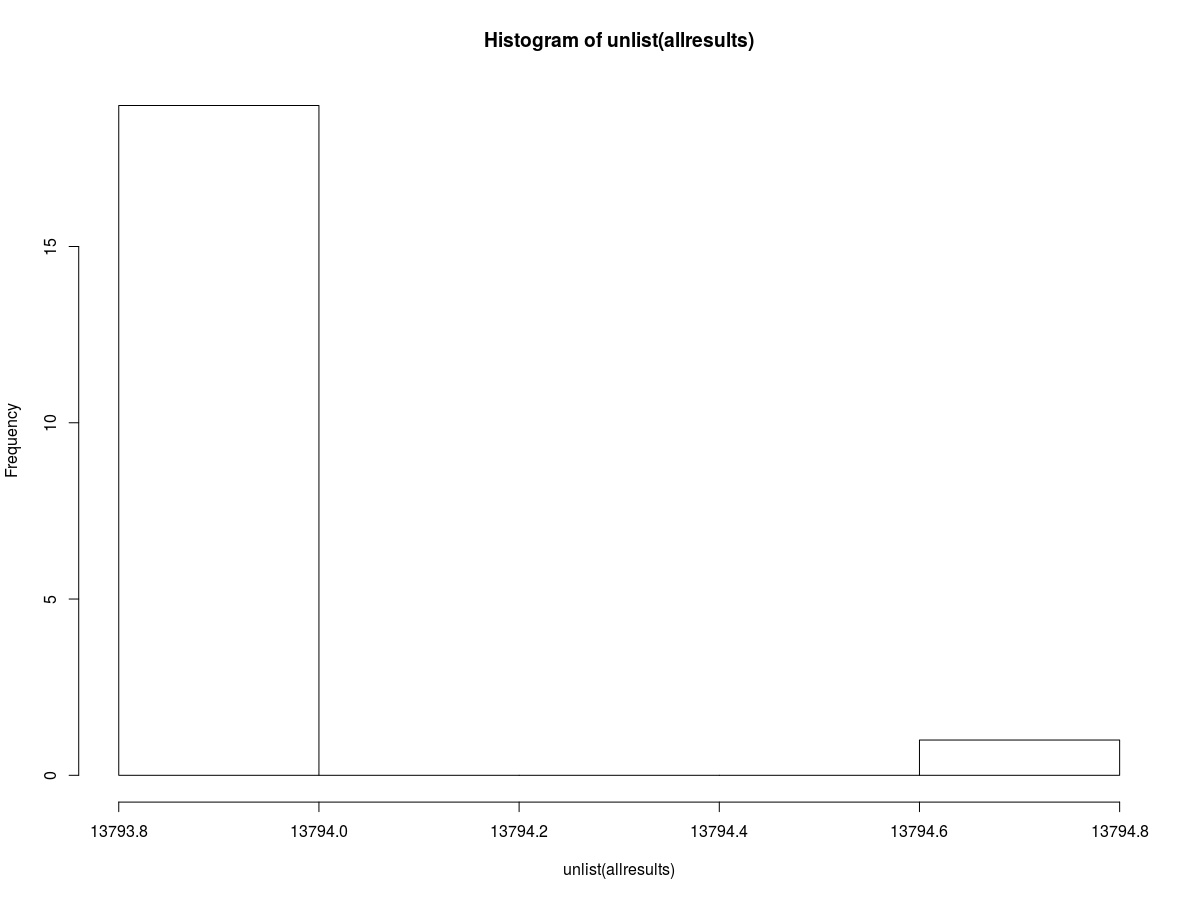
This is evidenced in the code example below. Running the same model 20 times over the same data creates up to 3 different quality metric after 50 rounds.
Differences are insignificant in terms of model quality, but very annoying in terms of reproducibility.
We could not replicate this behavior when using any of the CPU methods, or gpu_exact.
Also, it seems like it does not really happen with smaller amount of data (e.g. chaging 1e8 to 1e7 in code example below removes the issue).
Here’s session info for R:
R version 3.5.1 (2018-07-02)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 16.04.5 LTS
Matrix products: default
BLAS: /usr/lib/openblas-base/libblas.so.3
LAPACK: /usr/lib/libopenblasp-r0.2.18.so
locale:
[1] LC_CTYPE=en_AU.UTF-8 LC_NUMERIC=C LC_TIME=en_AU.UTF-8 LC_COLLATE=en_AU.UTF-8
[5] LC_MONETARY=en_AU.UTF-8 LC_MESSAGES=C LC_PAPER=en_AU.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C LC_MEASUREMENT=en_AU.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] xgboost_0.81.0.1
loaded via a namespace (and not attached):
[1] compiler_3.5.1 magrittr_1.5 Matrix_1.2-14 tools_3.5.1 stringi_1.2.4 grid_3.5.1
[7] data.table_1.11.8 lattice_0.20-35
Here’s an example to reproduce bug:
set.seed(1)
# generate data
example_data <- matrix(rnorm(1e8 / 2), nrow = 1e6)
example_response <- runif(nrow(example_data)) + exp(rowSums(example_data))
example_response[example_response > 1e5] = 1e5
example_weight <- runif(nrow(example_data), 0.1, 0.9)
train_data <- example_data[1:(nrow(example_data) * 0.8), ]
train_response <- example_response[1:(nrow(example_data) * 0.8)]
train_weight <- example_weight[1:(nrow(example_data) * 0.8)]
test_data <- example_data[-(1:(nrow(example_data) * 0.8)), ]
test_response <- example_response[-(1:(nrow(example_data) * 0.8))]
test_weight <- example_weight[-(1:(nrow(example_data) * 0.8))]
# Create Dmatrices
weighted_train <-
xgb.DMatrix(data = train_data,
label = train_response,
weight = train_weight)
weighted_test <-
xgb.DMatrix(data = test_data,
label = test_response,
weight = test_weight)
# Look for different results
allresults=list()
for(i in 1:20){
set.seed(123)
model <-
xgb.train(
data = weighted_train,
watchlist = list(train = weighted_train, test = weighted_test),
objective = "count:poisson",
nrounds = 50,
verbose = 1,
print_every_n = 50,
tree_method = "gpu_hist"
)
result <- model$evaluation_log[50,3]
allresults[[i]]=result
}
Hist of allresults after this code: