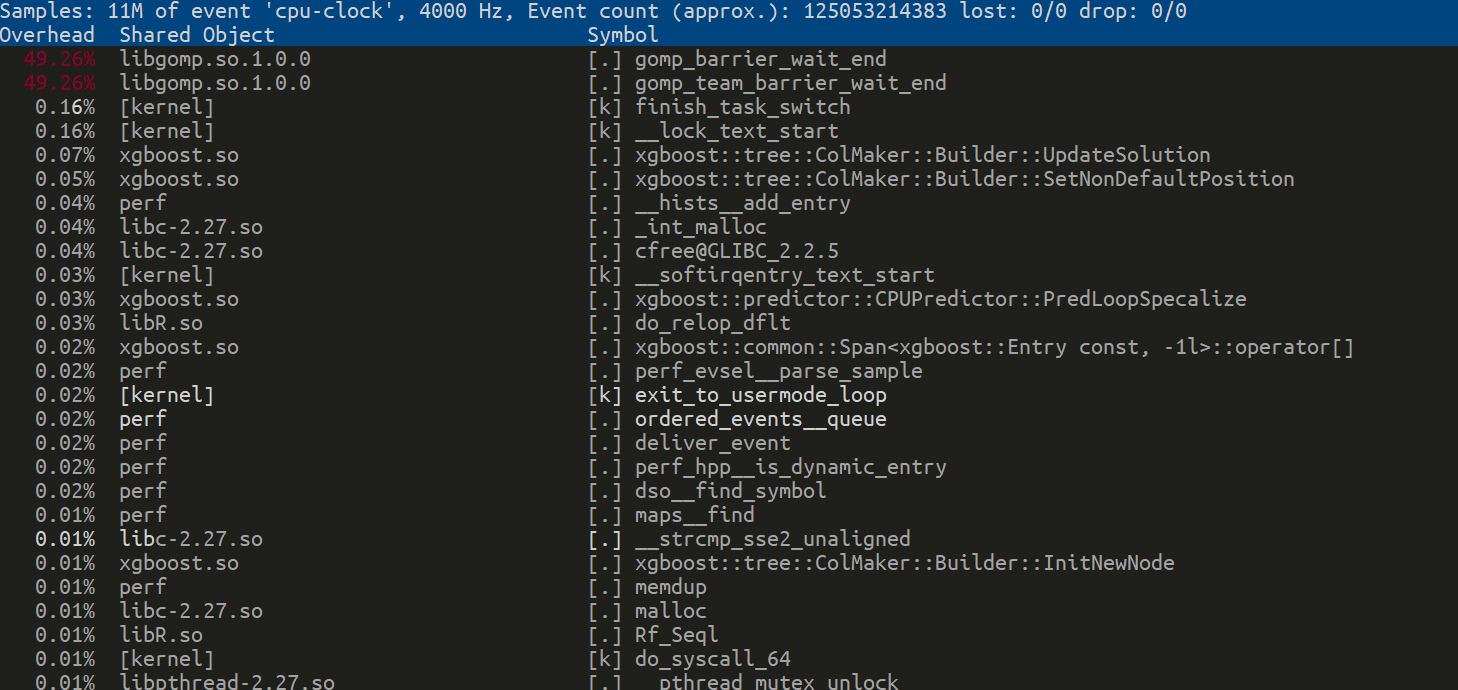
I observe lots of threads just busy waiting (threads calling do_spin()) around these openmp loops:
fsplits.push_back(tree[nid].SplitIndex());
}
}
std::sort(fsplits.begin(), fsplits.end());
fsplits.resize(std::unique(fsplits.begin(), fsplits.end()) - fsplits.begin());
for (const auto &batch : p_fmat->GetBatches<SortedCSCPage>()) {
for (auto fid : fsplits) {
auto col = batch[fid];
const auto ndata = static_cast<bst_omp_uint>(col.size());
#pragma omp parallel for schedule(static)
for (bst_omp_uint j = 0; j < ndata; ++j) {
const bst_uint ridx = col[j].index;
const int nid = this->DecodePosition(ridx);
const bst_float fvalue = col[j].fvalue;
// go back to parent, correct those who are not default
if (!tree[nid].IsLeaf() && tree[nid].SplitIndex() == fid) {
if (fvalue < tree[nid].SplitCond()) {
this->SetEncodePosition(ridx, tree[nid].LeftChild());
} else {
this->SetEncodePosition(ridx, tree[nid].RightChild());
}
const RegTree& tree) {
// set the positions in the nondefault
this->SetNonDefaultPosition(qexpand, p_fmat, tree);
// set rest of instances to default position
// set default direct nodes to default
// for leaf nodes that are not fresh, mark then to ~nid,
// so that they are ignored in future statistics collection
const auto ndata = static_cast<bst_omp_uint>(p_fmat->Info().num_row_);
#pragma omp parallel for schedule(static)
for (bst_omp_uint ridx = 0; ridx < ndata; ++ridx) {
CHECK_LT(ridx, position_.size())
<< "ridx exceed bound " << "ridx="<< ridx << " pos=" << position_.size();
const int nid = this->DecodePosition(ridx);
if (tree[nid].IsLeaf()) {
// mark finish when it is not a fresh leaf
if (tree[nid].RightChild() == -1) {
position_[ridx] = ~nid;
}
} else {
// push to default branch