
Hello!
My purpose is to include xgboost4j-spark into a dockerized spark/PySpark environment, to develop how to integrate PySpark with XGBoost-spark version (I know there was prototype online to integrate PySpark with XGBoost-spark but I need to dev some other functions.)
Environment I use is the dockerized spark/Pyspark is from below (but I changed a bit in order to include XGBoost .jar file for spark config, see below):
The advantage is this dockerized env allows me to use Scala under Jupyter notebook, instead of Scala in shell.
Some key env parameters:
HADOOP_VERSION 3.0.0
APACHE_SPARK_VERSION=2.4.5
What I did is to download compiled XGBoost fat jar version 1.0.0 scala version 2.12 from [maven central], and copied these .jar files (i.e xgboost4j_2.12-1.0.0.jar and xgboost4j-spark_2.12-1.0.0.jar) into spark config:
# Spark and Mesos config
ENV SPARK_HOME=/usr/local/spark
COPY ./src/xgboost4j_2.12-1.0.0.jar $SPARK_HOME/xgboost4j_2.12-1.0.0.jar
COPY ./src/xgboost4j-spark_2.12-1.0.0.jar $SPARK_HOME/xgboost4j-spark_2.12-1.0.0.jar
ENV PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip \
MESOS_NATIVE_LIBRARY=/usr/local/lib/libmesos.so \
SPARK_OPTS="--driver-java-options=-Xms1024M --driver-java-options=-Xmx4096M --driver-java-options=-Dlog4j.logLevel=info --jars=$SPARK_HOME/xgboost4j_2.12-1.0.0.jar,$SPARK_HOME/xgboost4j-spark_2.12-1.0.0.jar --driver-class-path=$SPARK_HOME/*.jar --conf spark.executor.extraClassPath=$SPARK_HOME/*.jar" \
PATH=$PATH:$SPARK_HOME/bin
I can open a kupyternook with Scala run in it. I can also run Spark from this jyputer, I can also import xgboost without error reported.
Call for help : The problem I met is that when I actually call XGBoostClassifier, I got java.lang.NoSuchMethodError :
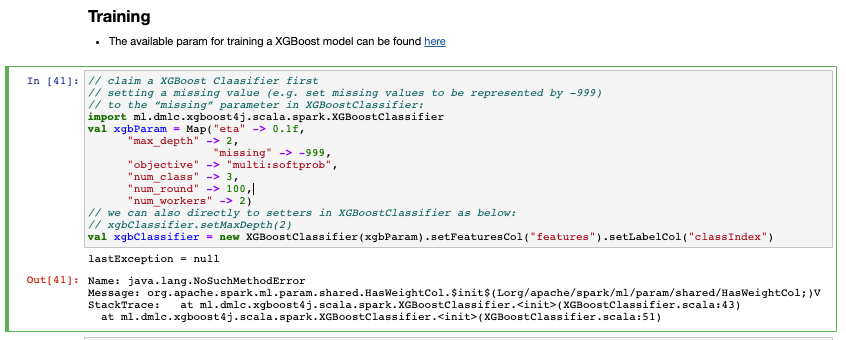
(P.S since I am new to community, I can only attach 2 links in one post, so more detailed info is attached to my reply.)
Thank you so much for your help! Any advice is appreciated!
