
I’ve tried to use XGBoost model to finish a Chinese medical FAQ dialog system, that means to choose a most similar question from candidates to the user input. During test it, I find a very strange thing. When I use the trained model that I have saved to test the same data many times, it will give different prediction probability. I don’t know that’s why. Can someone tell me?
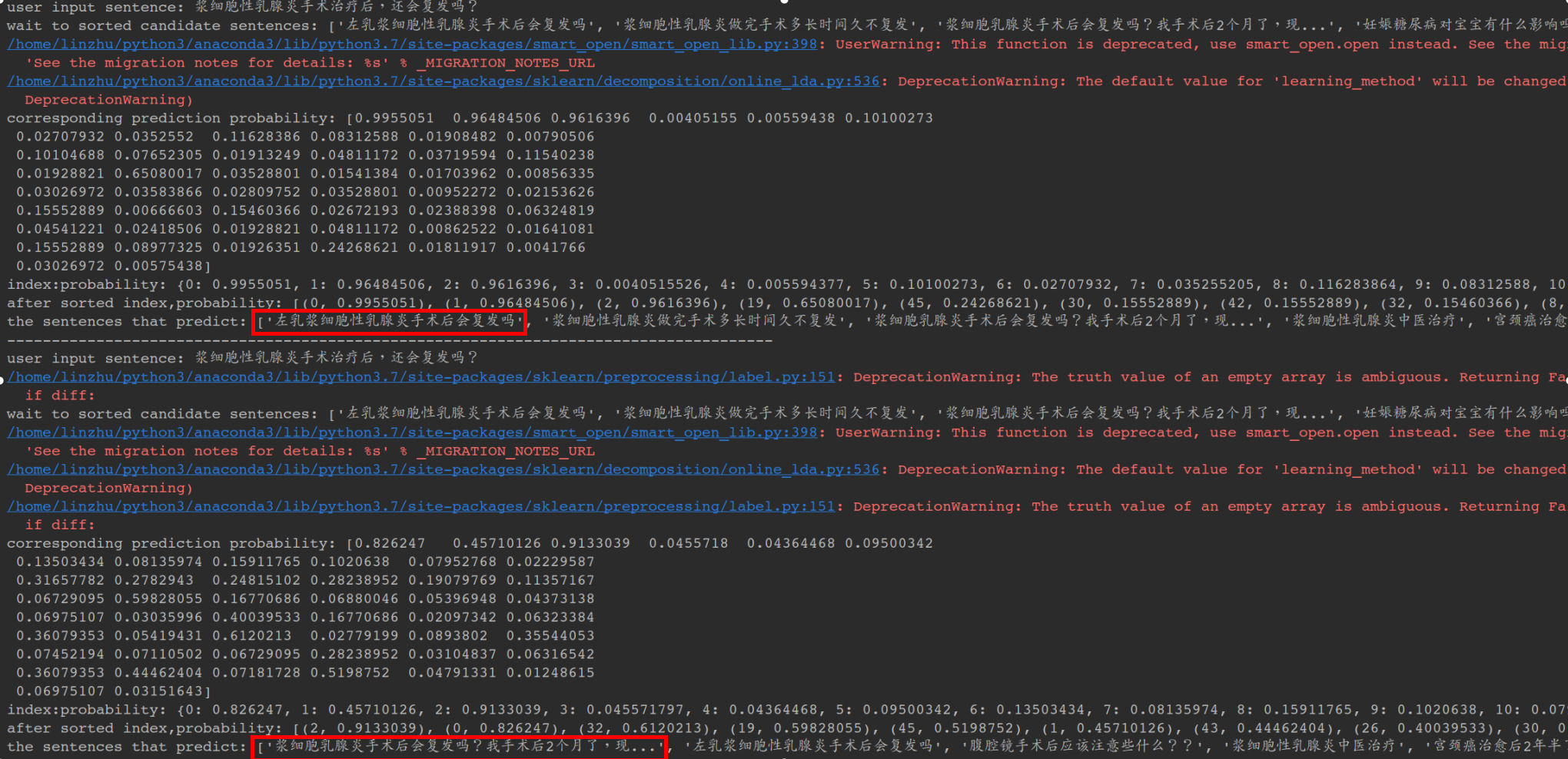
Here’s my result:
Here’s my code:
def my_model():
sent_pairs=[]
with open('/home/linzhu/Desktop/medical_bot/formal_test/test_model/tt.txt', 'r', encoding='UTF-8-sig') as f1:
file_content = f1.read()
lines = file_content.split('\n')
for line in lines:
sent_pairs.append(line.split('\t'))
# sent_pairs=[['卵子冻存和卵巢组织冻存有什么区别?', '冻卵卵巢组织冻存有什么意义?', '0'],[],...,[]]
index=0
while index<len(sent_pairs):
q_candidate_sents=[]
q_candidate_words=[]
q_input_sent=sent_pairs[index][0]
print('user input sentence:',q_input_sent)
q_input_word = devide_results(devide_words_pos_delete_stopwords(q_input_sent))
for i in range(50):
q_candidate_sents.append(sent_pairs[index+i][1])
for q_candidate_sent in q_candidate_sents:
q_candidate_words.append(devide_results(devide_words_pos_delete_stopwords(q_candidate_sent)))
print('wait to sorted candidate sentences:',q_candidate_sents)
features = get_all_features(q_input_sent, q_input_word, q_candidate_sents, q_candidate_words)
XGBclmodel = joblib.load("/home/linzhu/Desktop/medical_bot/backend/ML_model/XGB_cl_model.m")
pred_list = XGBclmodel.predict(features)
pred_proba=XGBclmodel.predict_proba(features)[:,1] #取第二列作为概率,因为系统并不知道哪种符号是(0 or 1)正样本
print('corresponding prediction probability:',pred_proba)
tp = np.argwhere(pred_list >= 0) # 获取所有的索引
positive_index_proba = {} # 存储 {索引:概率}
for i in tp:
positive_index_proba[int(i)] = pred_proba[int(i)]
print('index:probability:',positive_index_proba)
proba_list = sorted(positive_index_proba.items(), key=lambda item: item[1], reverse=True)
print('after sorted index,probability:',proba_list)
# print(proba_list) #proba_list=[(0,0.99),(6,0.78),...,(99,0.58)]
predict_sents=[]
for ea in proba_list:
predict_sents.append(sent_pairs[index+ea[0]][1])
print('the sentences that predict:',predict_sents)
print('--------------------------------------------------------------------------------------')
# with open('/home/linzhu/Desktop/medical_bot/formal_test/test_model/1to50/my_model.txt', 'a+', encoding='UTF-8-sig') as f:
# print(predict_sents[0]+'\n')
# f.write(q_input_sent+'\t'+'\t'.join(predict_sents)+'\t'+sent_pairs[index + proba_list[0][0]][2]+'\n')
index+=50
index=40
while(index>0):
my_model()
index-=1
and tt.txt likes this, example row, the total of rows is 50:
浆细胞性乳腺炎手术治疗后,还会复发吗? HPV检查一般多久出结果,接种HPV疫苗后还需要吗 0