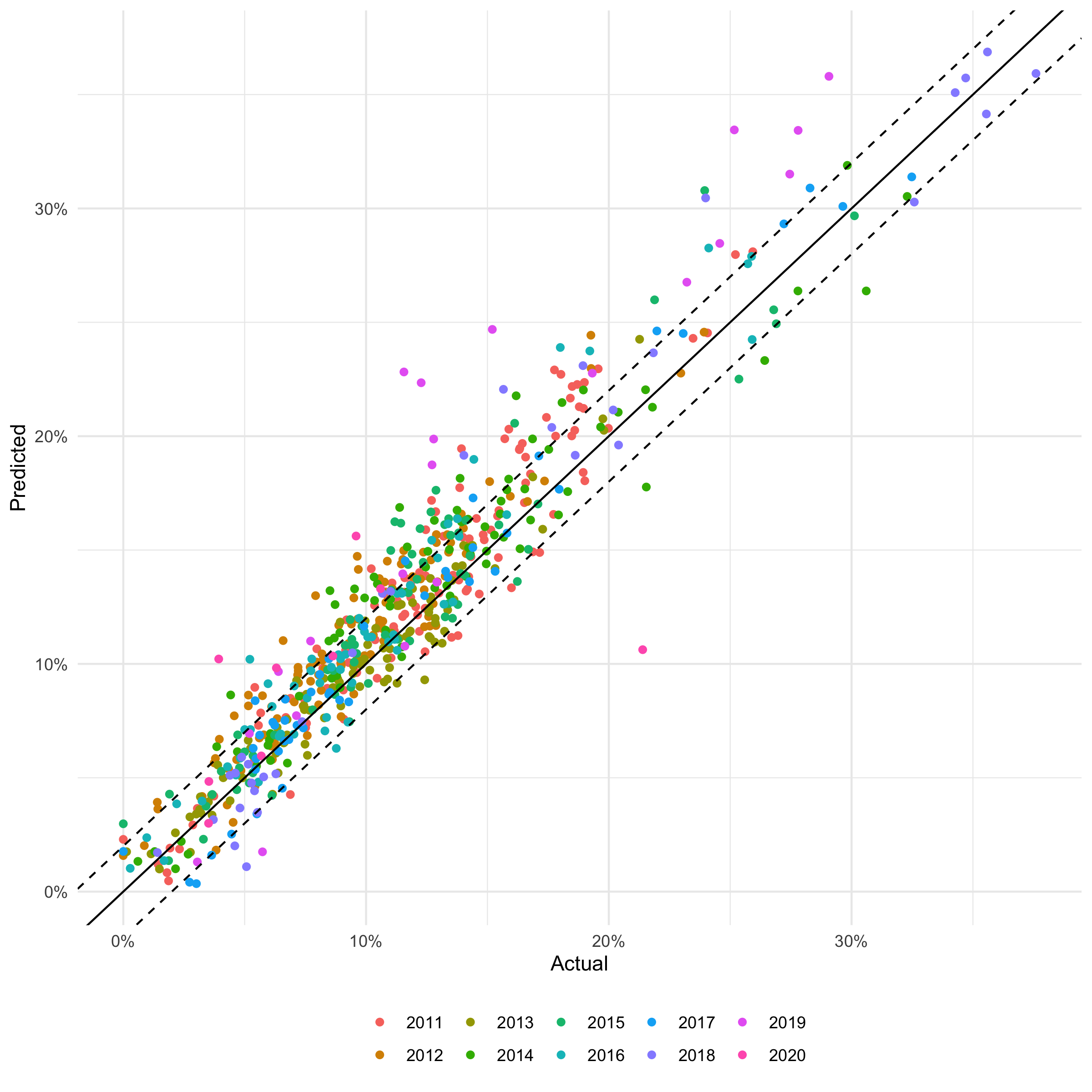
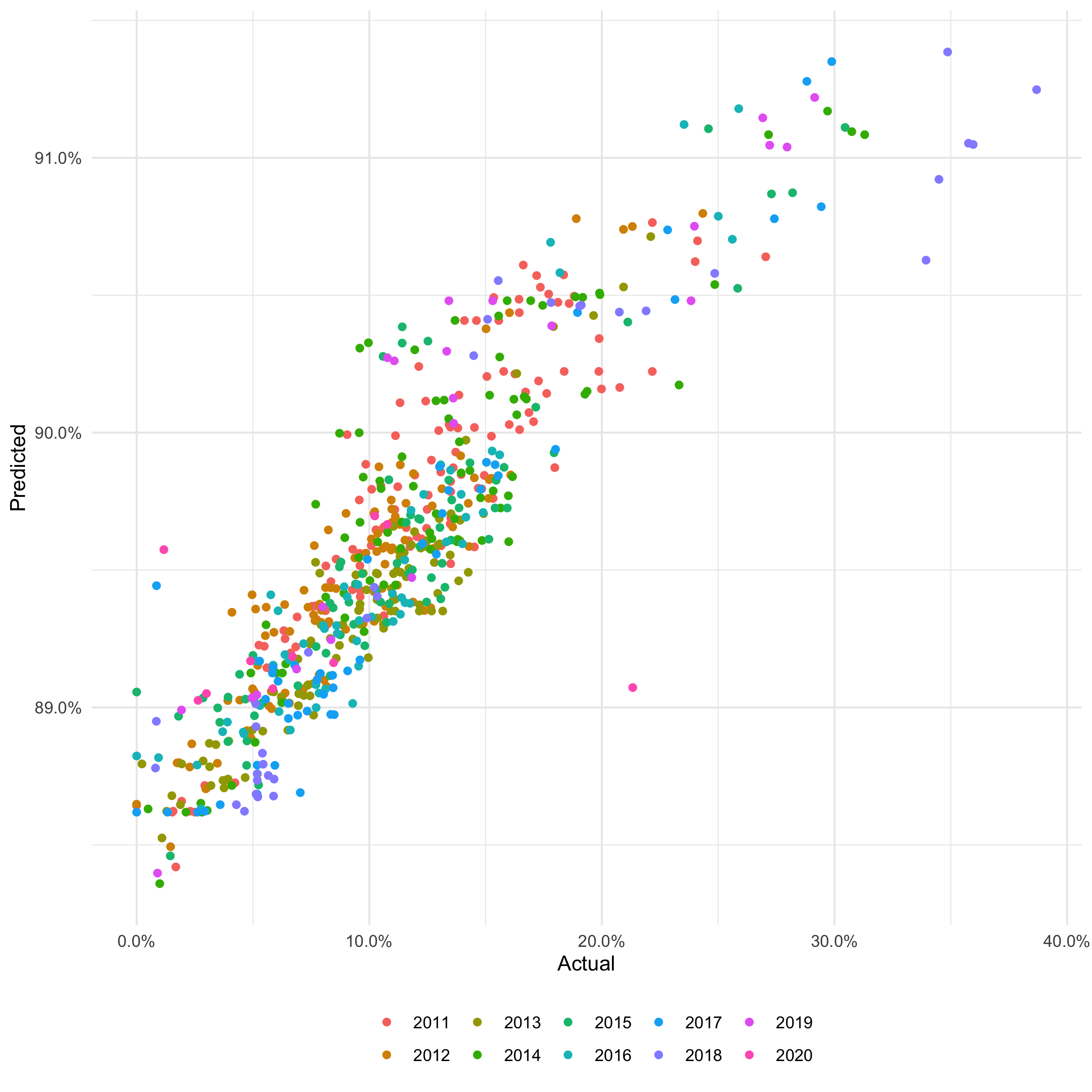
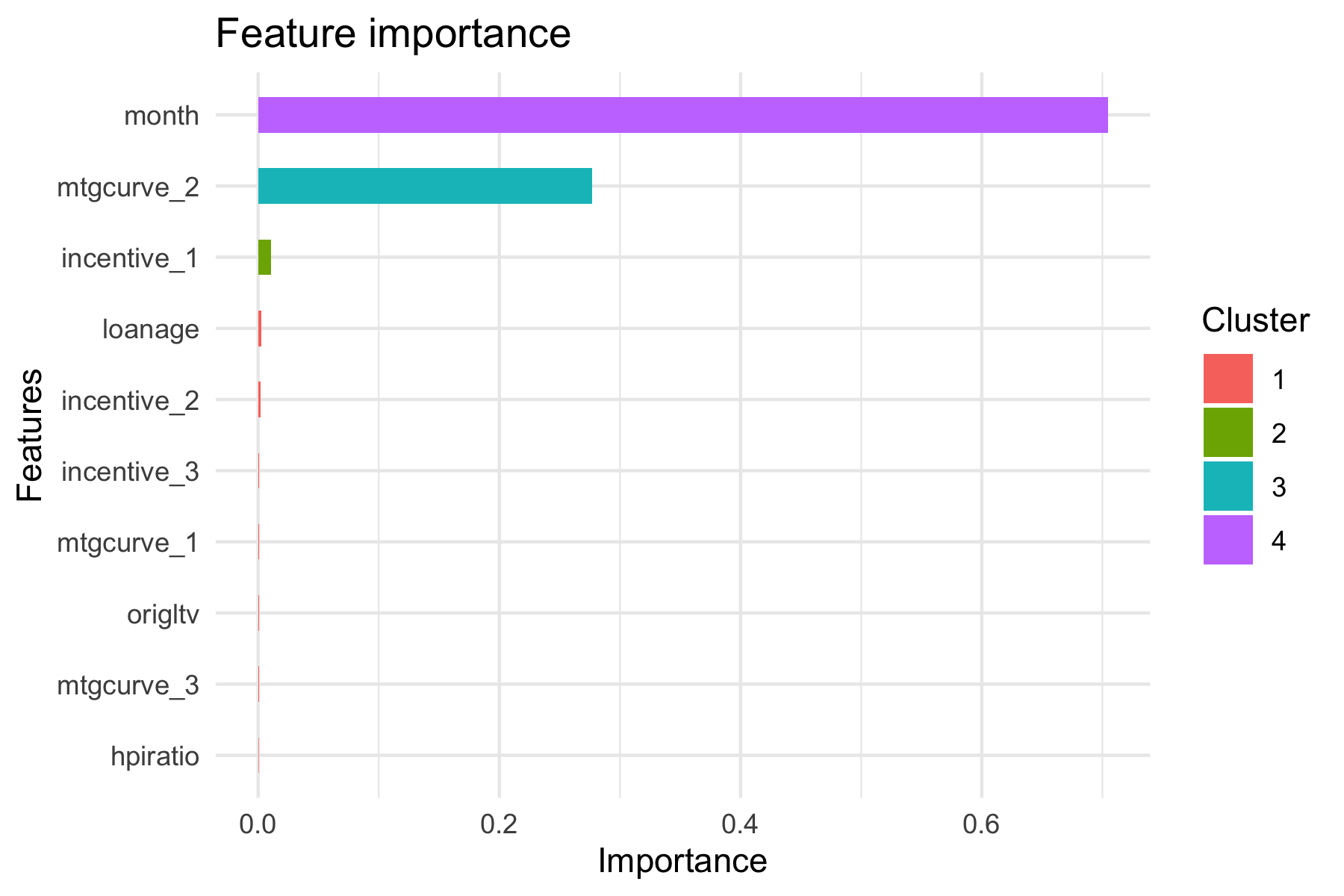
If anyone can help me understand the below behavior
- Using a lower learning rate say .01 and more trees I end up with a poorer model as measured by auc.
- Using a higher learning rate say .4 and fewer trees I end up with a superior model as measured by auc.
A smaller and more performant model is preferable to a larger less performant model. So, I am happy with the results. Still, the outcome is different that what I have learned with respect to boosting with respect to learning rate and number of trees. I suppose it is simply the difference in classifiers. Still, I would like to understand the why as best possible as I plant to replace the old classifier with XgBoost in a production environment next year.
The dataset is highly unbalanced . Below is the parameter setup.
trainlabel <- trainloandata$event
trainpred <- trainloandata[,!(names(trainloandata) %in% c('event'))]
dtrain <- xgb.DMatrix(data = data.matrix(trainpred), label = trainlabel)
testlabel <- testloandata$event
testpred <- testloandata[,!(names(testloandata) %in% c('event'))]
dtest <- xgb.DMatrix(data = data.matrix(testpred), label = testlabel)
params <- list(booster = "gbtree",
objective = "binary:logistic",
tree_method = 'approx',
eta = 0.4,
gamma = 0,
max_depth = 8,
max_delta_step = 2,
min_child_weight = 1,
subsample = .5,
colsample_bytree = 1.0)
params_constrained <- params
watchlist <- list(train = dtrain, test = dtest)
xgboost_model <- xgb.train(params = params,
data = dtrain,
nrounds = 500,
watchlist = watchlist,
print_every_n = 1,
early_stopping_rounds = 5,
maximize = TRUE,
eval_metric = "auc",
metric_name = "dtrain_auc")