
Hi,
I’ve noticed that xgboost does not seem to take into account the complexity of the cut when comparing a subset split criteria vs. a cut on a numerical feature.
For example, in the below, even though the target depends only on feature a, xgboost chooses to cut almost entirely on feature b.
import pandas as pd
import numpy as np
import xgboost as xgb
X = pd.DataFrame({'a': np.random.uniform(-1, 1, 10000), 'b': (list(range(5000)) * 2)})
y = X['a'] + np.random.normal(0, 5.0, 10000)
ft = ['q', 'c']
Xy = xgb.DMatrix(X, y, feature_types=ft, enable_categorical=True)
model = xgb.train({"tree_method": "hist", "max_cat_to_onehot": 5, 'base_score': 0.0, 'lambda': 5.0, 'max_cat_threshold': 5000}, Xy, num_boost_round=1)
model.trees_to_dataframe().head(20)
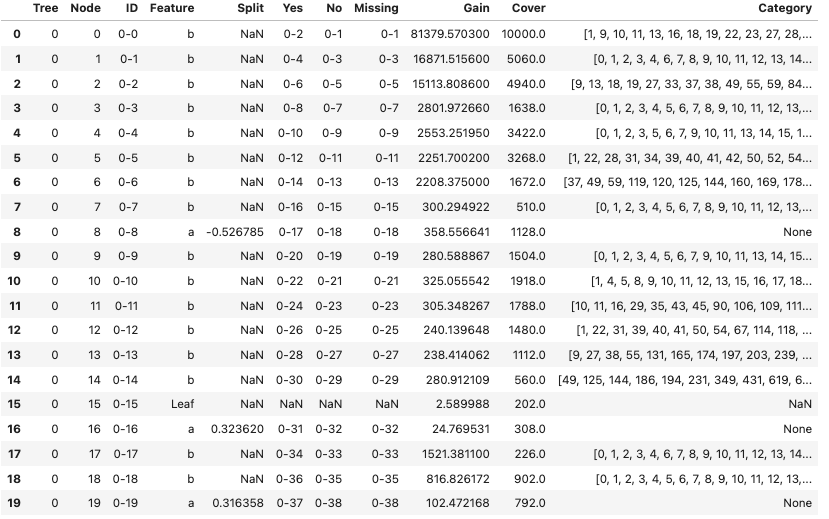
Is it possible to penalize complex cuts like these in order to reduce the likelihood of xgboost cutting on this feature?