
I have a couple of questions related to parallelism in the Python api. I’m using XGBRegressor() with ‘tree_method’: ‘hist’ and other default parameters in a kaggle cpu kernel (4 cores) on the Ames Housing dataset (~80 features, ~1500 samples). I run a couple of tests (100 iterations for each condition). It seems the n_jobs parameter (left panel) doesn’t make any difference to fit time (y axis) until we specify n_jobs greater then the number of available cores:
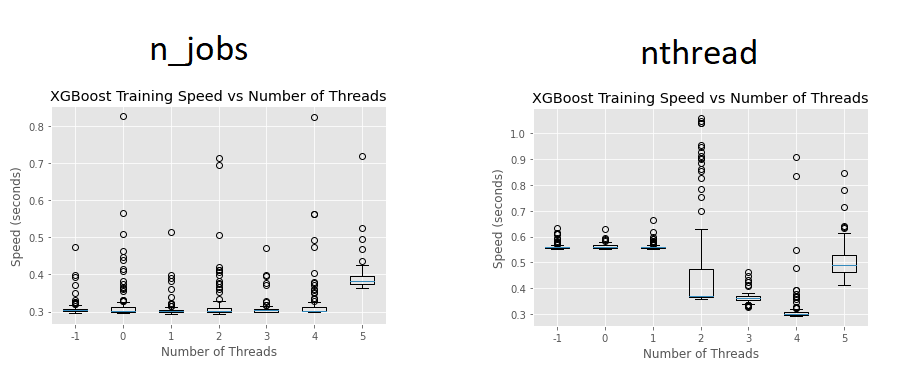
Does it mean that n_ jobs will be set to the max number of available cores automatically (unless we set it to something greater than the number of cores)?
I also tested the same range of values for the ‘nthread’ parameter (right panel). Here it seems that it actually makes a difference and performance is best for the maximum number of available cores (4).
Could anyone explain the different behaviour of the two parameters? Which of the two parameters should we use in the Python api?