
Hello,
My dataset has ~ 50k observations, distributed through 8 predictive features and one output (target): all continuous values, whose input features were normalized in a scale between 0-1 and the target by a Box-cox transformation.
So I got the machine learning for artificial neural networks, support vector machine and xGBoost. Besides that, the dimensional analysis (relation of dimensionless groups with coefficients estimated by least squares method) was made before as standard method.
However, I would like to know if I can make the xGBoost setting even smoother (this phenomenon is usually expressed in a power law curve). I realized that max_depth allows this in a way, since it makes the model as simple as possible. I also tried to adjust other values in hyperparameters as a precautionary measure to overfitting.
My current parameters are:
XGBRegressor (base_score = 0.5, booster = ‘gbtree’, colsample_bylevel = 1, colsample_bytree = 0.9, eta = 0.1, gamma = 0, importance_type = ‘gain’, learning_rate = 0.1, max_delta_step = 0.8, max_depth = 2, min_child_weight = 5, missing = None, n_estimators = 5000, n_jobs = 1, nthread = None, objective = ‘reg: linear’, random_state = 0, reg = ‘logistic’, reg_alpha = 0, reg_lambda = 1, scale_pos_weight = 1, seed = None, silent = True, subsample = 0.9, tree_method = ‘approx’, verbose = 2)
A comparative chart between models:
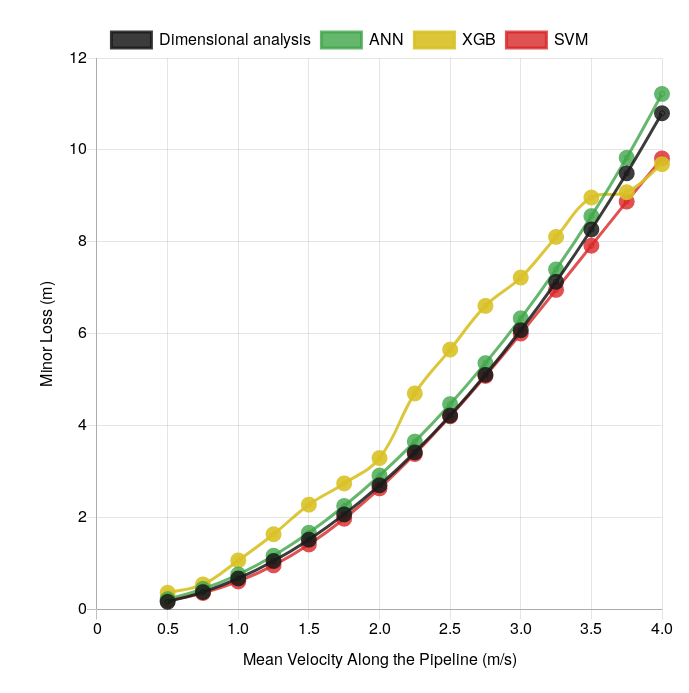
Is it the nature of the tree decision to work with this nested condition that makes the model so, or can I smooth the fit?
Many thanks!