
When removing (unimportant) features to certain level, I got a suprisingly short training time, which worried us if the implementation is faulty. Could you please comment how to debug or if that is expected behavior?
The plot below shows the sudden change in training time when just removing some features. It seems the pattern is stable.
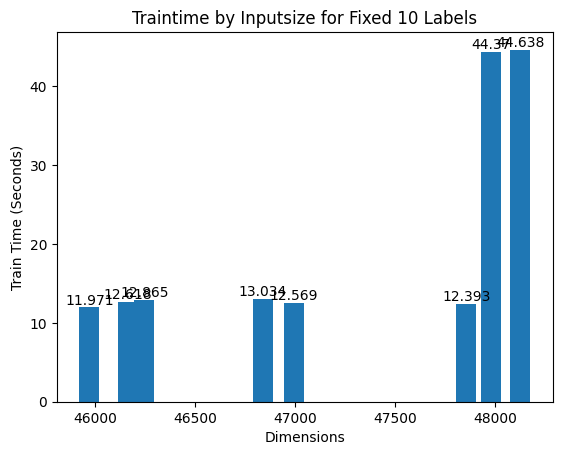
Training Parameters
BOW_XGB_init = xgb.XGBClassifier(n_estimators=100, max_depth=1, learning_rate=0.1,silent=False, objective='binary:logistic', \
booster='gbtree', n_jobs=32, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, \
subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1)
System:
128 physical cores; 256 GB memory; Ubuntu 22.04.2; python3.10.12
Thanks,
Zongshun