
Hi,
I’m trying to use XGboost on a quite large Dataset (~500G) on Yarn, and keep getting below error when running stage-1 foreach partition after successfully run stage 0-repartition and will keep retry step 0.
Stage Screenshot:
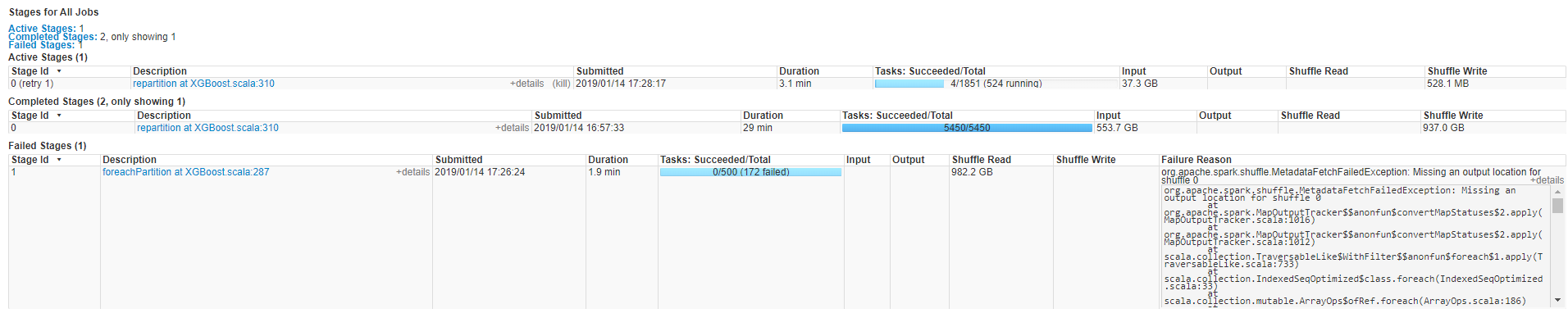
I’m wondering is this because of the program doesn’t get enough resource from the cluster?
The program ran pretty well on a sample set, can someone take a look at it?
Thanks!!